Banking Challenges on Cash Management
Custom Made solutions
Traditional approach
:
✓ Outlier Detection
✓ Handling Missing Values
✓ Normalisation
✓ Feature Engineering
✓ Feature Selection
Options

VertexAI provides an easy-to-use interface for loading and preprocessing data, which can be used to load transaction data and other relevant data such as weather information and economic indicators.
Read More
VertexAI includes a number of pre-built ML models that can be used to train models on the data. It also allows users to create their own custom models using the drag-and-drop interface.
Read More
VertexAI allows for easy deployment of trained models. This means that once a model is trained, it can be deployed in a production environment and used to make predictions in real-time
Read MoreVertexAI provides monitoring tools that allow users to track the performance of the deployed models over time. This helps to ensure that the models continue to make accurate predictions
Read More
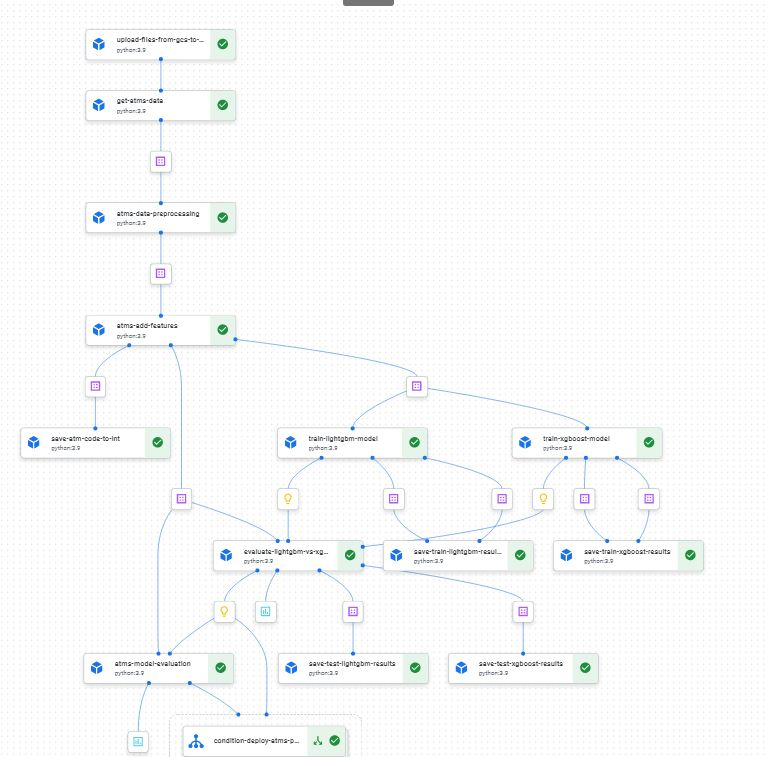
The first step is to collect the data needed to train the model. This includes data from previous transactions, as well as any additional data that may be relevant, such as weather information and economic indicators

Once the data is collected, it needs to be prepared for training. This includes cleaning the data, removing any inconsistencies or outliers, and normalizing the data

Next, a machine learning model needs to be selected. It could be a pre-built model or a custom model created by the user. The model should be appropriate for the task at hand and capable of handling the data set
Once the model is selected, it can be trained on the prepared data. The goal of this step is to train the model to make accurate predictions about cash demand
After the model is trained, it should be evaluated to ensure that it is making accurate predictions. This can be done by comparing the predictions made by the model to the actual cash demand
Once the model is trained and evaluated, it can be deployed in a production environment. This can include publishing the model to a variety of different platforms, such as web, mobile, and IoT devices, to make it available for use in real-time


Evaluate the performance of the current model and improve as needed

Determine ICT track routing to curtail costs further

Scale to the entire ATM network / Include the entire branch cash demand

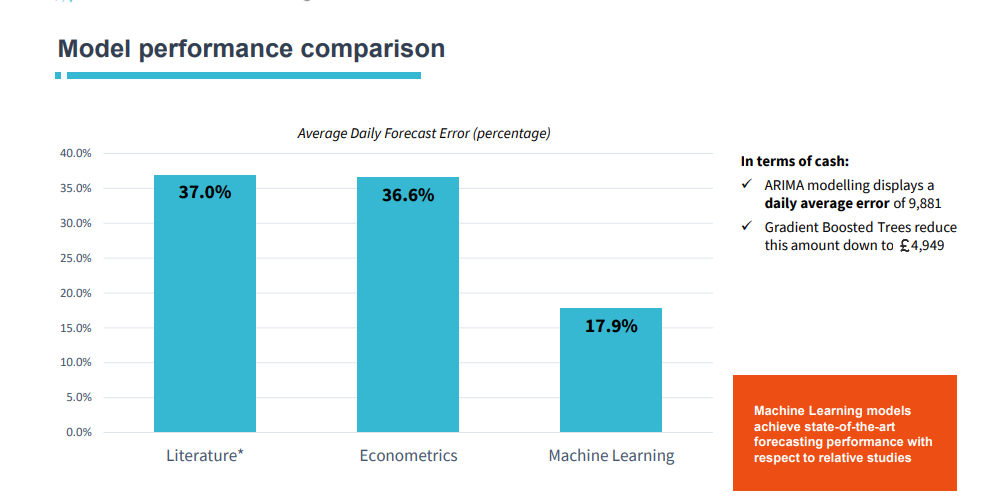
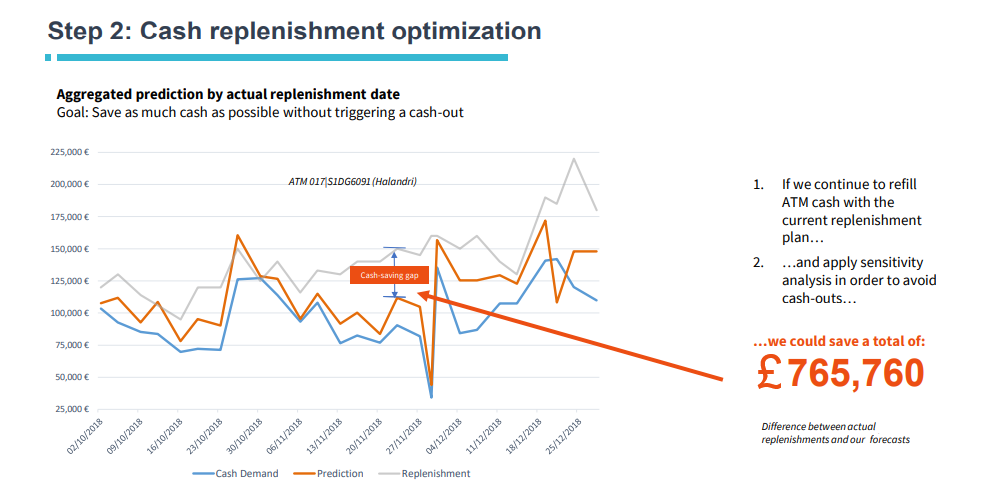
Accurately predict the cash demand per ATM
Our solution:
Roadmap